Abstract
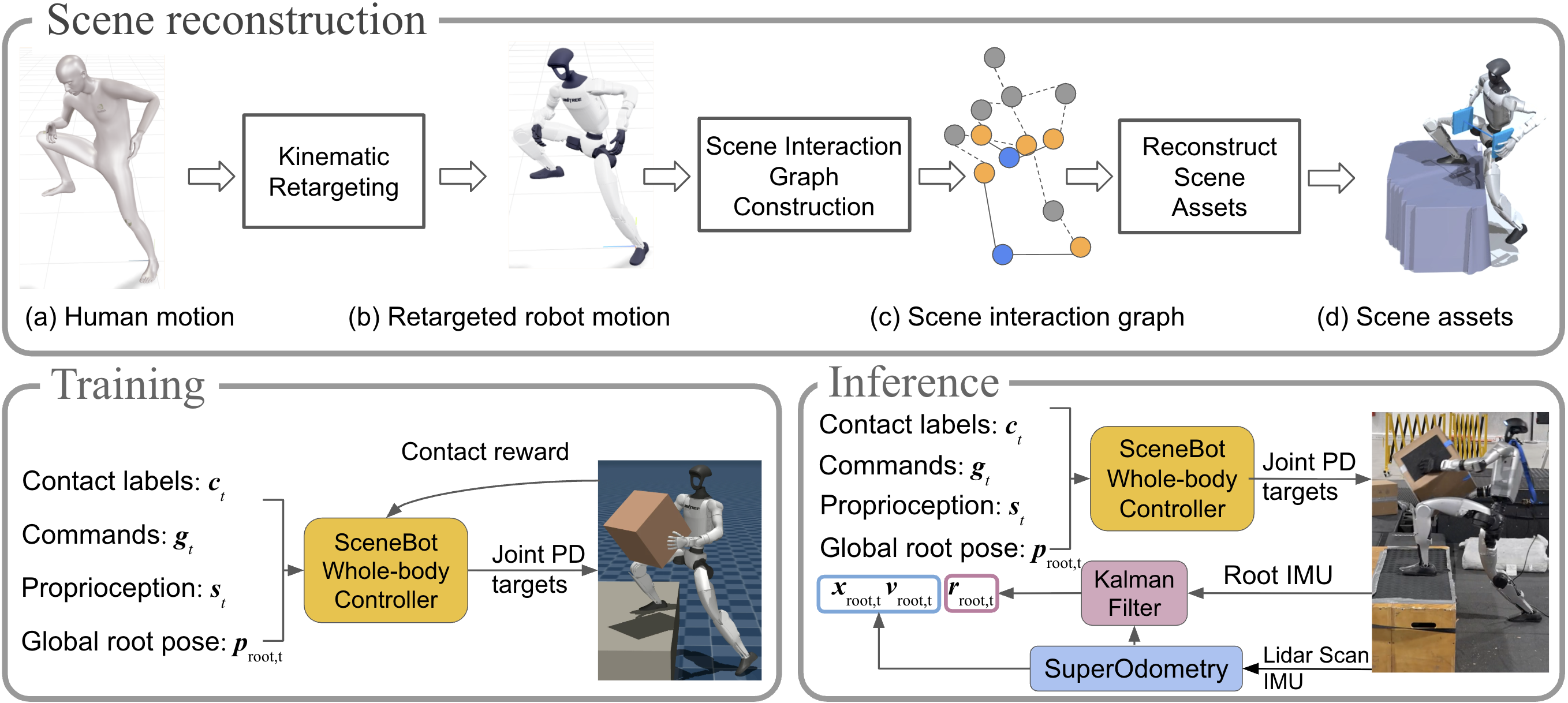
Current humanoid reinforcement-learning policies excel at free-space motions but struggle with contact-rich tasks, as pure kinematic tracking cannot resolve the physical ambiguities of interacting with objects and uneven terrain. To address this, we introduce SceneBot, a unified motion-tracking framework capable of handling freespace locomotion, terrain traversal, and whole-body manipulation. SceneBot conditions a single policy on both reference motions and per-link contact labels, explicitly defining expected environmental interactions. To overcome the lack of annotated interaction data, we propose a hindsight scene reconstruction approach that infers scene-interaction graphs from retargeted human motion. Trained on 7.5 hours of this reconstructed, contact-rich data, SceneBot successfully generalizes to unseen motions and environments. Our results demonstrate that SceneBot is the first general framework to seamlessly unify free-space and contact-rich behaviors—executing complex, long-horizon tasks like carrying a box upstairs and establishing contact conditioning as a powerful interface for humanoid control.